What are Vectors?
Understanding how text becomes searchable through vector embeddings and similarity search
What are Vector Embeddings?
A vector (also called an embedding) is a numerical representation of text, images, or other data. Think of it as translating human language into a mathematical format that computers can understand and compare.
When you convert text into a vector, you're creating a list of numbers (typically 384, 768, or 1536 numbers) that captures the meaning and context of that text. Similar pieces of text will have similar vectors.
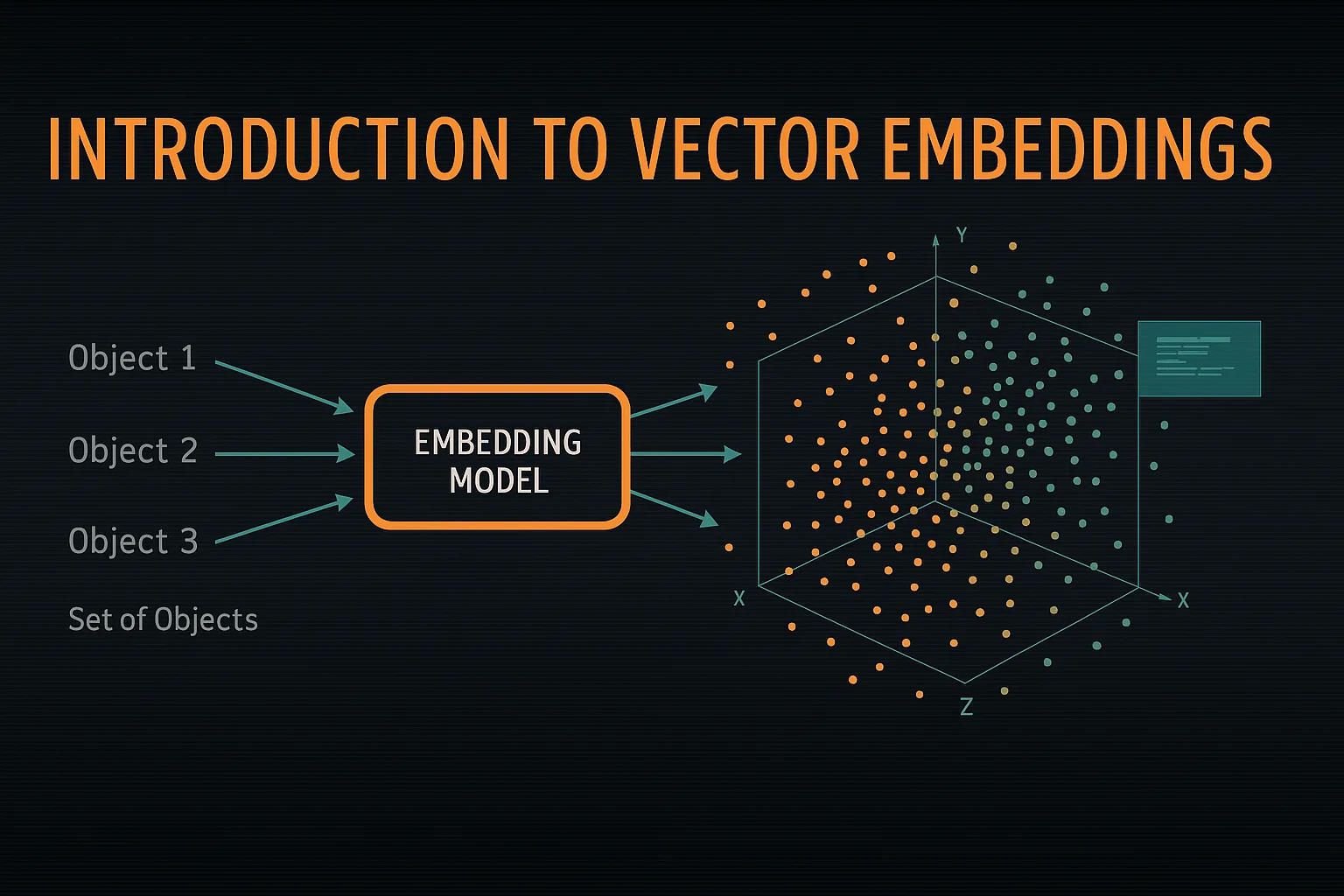
The diagram above illustrates how distinct objects are transformed by an embedding model into points (vectors) within a multi-dimensional space. Objects that are similar in meaning will be positioned close to each other in this vector space, while dissimilar objects will be farther apart. This spatial representation allows computers to understand and compare semantic relationships.
Example: The phrases "How do I ship bread?" and "What are your shipping options?" will have very similar vectors, even though the words are different.
How Vectors are Searchable
Vectors are searchable because we can mathematically measure how similar they are to each other. When you search for something, the system:
1.Converts Your Query to a Vector
When you ask a question, that question is converted into a vector using the same embedding model that was used to index your content.
2.Calculates Similarity
The system compares your query vector against all the vectors in the database using cosine similarity to find the most similar content.
3.Returns Most Relevant Results
The vectors with the highest similarity scores are returned as the most relevant results, even if they don't contain the exact same words as your query.
Understanding Cosine Similarity
Cosine similarity is a mathematical measure that calculates how similar two vectors are, regardless of their size. It measures the angle between two vectors in multi-dimensional space.
How It Works
- • Cosine similarity returns a value between -1 and 1
- • 1.0 = Identical meaning (vectors point in the same direction)
- • 0.0 = No similarity (vectors are perpendicular)
- • -1.0 = Opposite meaning (vectors point in opposite directions)
Why Cosine Similarity?
Unlike simple keyword matching, cosine similarity understands semantic meaning. It can find relevant content even when the exact words don't match, making it perfect for natural language search.
Visualizing Vector Comparison
The diagram below illustrates how vectors are compared using cosine similarity. With a limited number of dimensions (like the 4 shown here), different entities might appear quite similar in vector space.
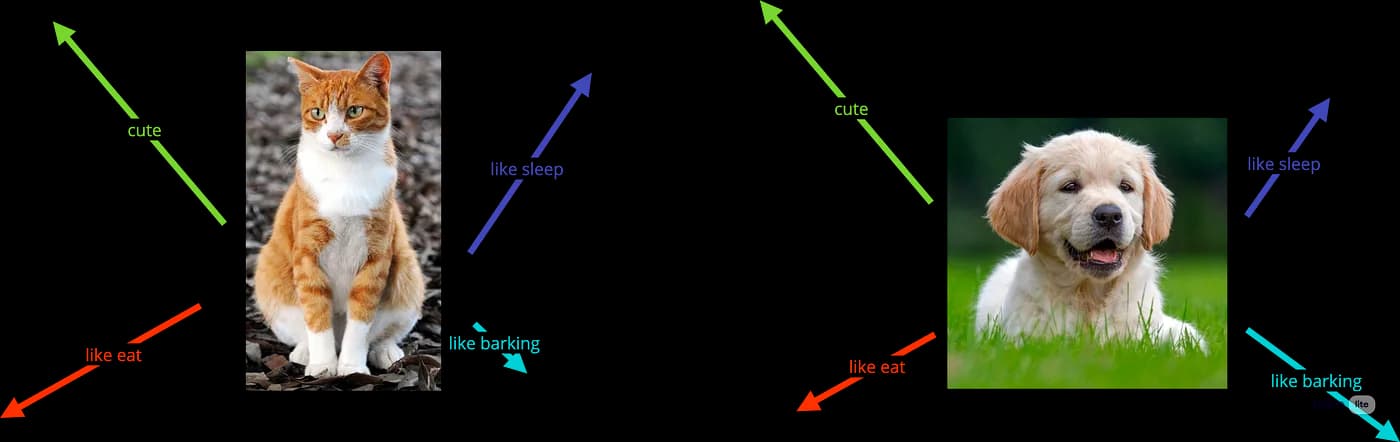
In this simplified example with 4 dimensions ("cute," "like sleep," "like eat," "like barking"), cats and dogs might appear very close in vector space because they share many attributes. However, by introducing more dimensions and distinct features, their differences become much clearer.
This is why vector density is important. Embedding models typically use 384, 768, or 1536 dimensions (or even more) to capture the nuanced differences between entities. The more dimensions you have, the better you can distinguish between similar but distinct concepts. For example, a cat's vector for "like barking" would be very low or zero, while a dog's would be high—this distinction becomes clear with higher-dimensional embeddings.
Example: A query about "shipping bread" will find documents about "delivery options for baked goods" even though they use different words, because the vectors are semantically similar.
The Vector Search Process
Step 1: Indexing
Your documents are split into chunks, each chunk is converted to a vector, and all vectors are stored in a vector database.
Step 2: Query
When a user asks a question, the query is converted to a vector using the same embedding model.
Step 3: Similarity Search
The database calculates cosine similarity between the query vector and all stored vectors, ranking them by similarity score.
Step 4: Retrieval
The top N most similar vectors (and their original text) are returned as context for the AI to generate a response.
Learn More
Vectors are stored in specialized vector databases that are optimized for fast similarity search. Learn about the different options available for your project.
See how vectors fit into the bigger picture in our RAG explanation.
At VERTEKS.AI, we integrate embeddings, databases, and retrieval pipelines to power private, high-performance AI systems — designed for real business environments, not just research labs.